
Over the weekend of 29 Nov to 1 Dec 2019, CorrelAid held the annual meetup for its network of data scientists who want to use their skills for Societal Good - this year it took place in Berlin. This meetup for volunteers, by volunteers had us teaching ourselves skills, sharing success stories and lessons learned, and hacking our way through open data sources.
The term data scientist is one with a vague definition. We’ve been described as data experts that use the scientific method; as better statisticians than software developers and better developers than a statistician; social scientists that know how to code; data storytellers; machine learning experts; Unicorn ninja rockstars.
With the exception of that last one, each of us identifies ourselves with some of these descriptions more than others, and they all touch a bit upon what it means to be a data scientist. But there is a certain magic to when these are all combined. The common thread throughout the whole weekend is that each and every person there is convinced that data, stats and tech should be used to benefit society as a whole, and the best bet to make that change lies in the combination of the multitude of disciplines attached to data science.
Each person at this weekend had skills and expertise in a different domain, and was humble enough to know that they don’t know everything, and need and want to learn from each other.
Full house beim Eröffnungsabend des @CorrelAid Meeetups, was das ganze Wochenende im @citylabberlin zum Thema Data Science und Open Data stattfinden wird 🎉
— Alexandra Kapp (@lxndrkp) November 29, 2019
ich freu mich auf interessante Talks, Workshops und vorallem die deutschlandweit angereisten CorrelAider 😊 #openData4good pic.twitter.com/hxGHEIjS2a
These 2,5 days have been a whirlwind of community driven talks, workshops, brainstorms and mini-hackathons. There was something for the aspiring data scientist to the seasoned veteran in the field and the hardcore academic statistician to the software hacker.
There were introduction primers to broaden a data scientist’s toolkit to prepare them for the tools they’ll most probably touch in their career: API’s, Git, Linux, and test driven development all wrapped around fun workforms like scavenger hunts and connecting to pasta databases. The boundaries between R and Python developers were cracked open in sessions as well (though I’ll stay true to Python).
An additional focus was placed on the nitty gritty of making a machine learning model: From feature engineering and handling missing data, to making your model (locally) explainable, and how to get everything in production and automated using the tools available from cloud providers.
Meetup is up and running. 🎉 Happening right now: Rahel is talking about "explanable ML" #opendata4good pic.twitter.com/iBbl9S4lVL
— CorrelAid (@CorrelAid) November 30, 2019
Of course, it would not be a CorrelAid meetup without the many mini-hackathons and spontaneous break-out sessions, all of them sharing the theme of open data: from using the GLEIF connector to using the datenguide connectors we developed in a previous project ( R, Python ) to visualize how much trash each of Germany’s regions accumulates over time.
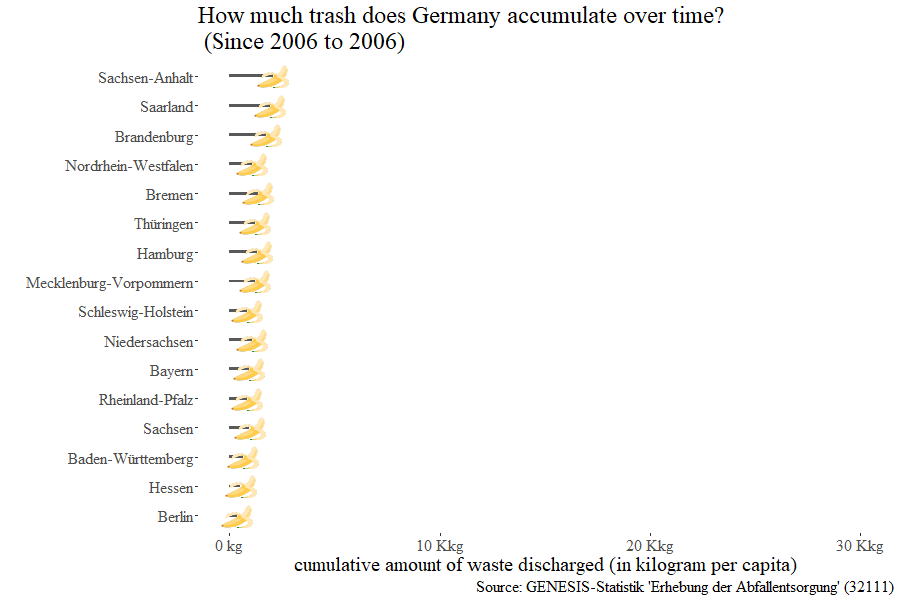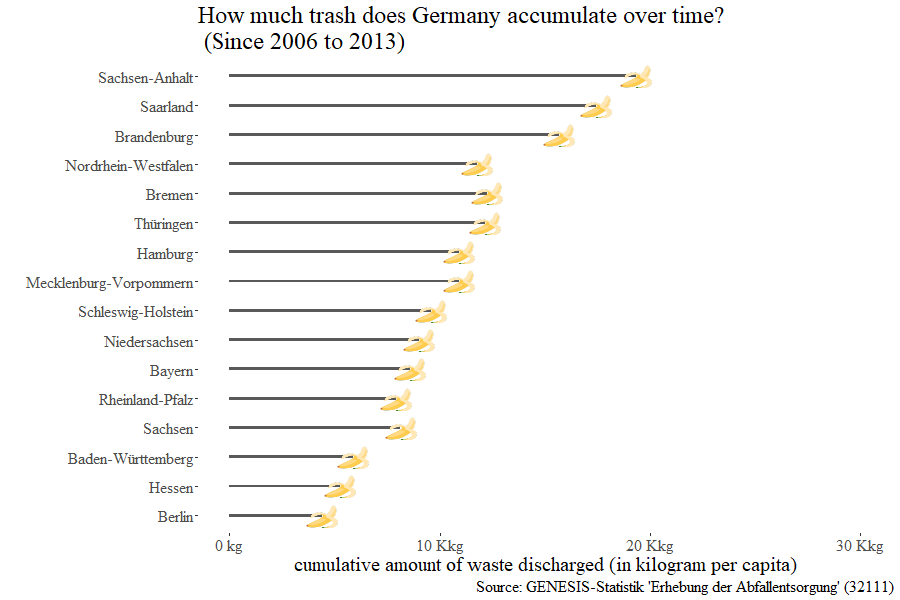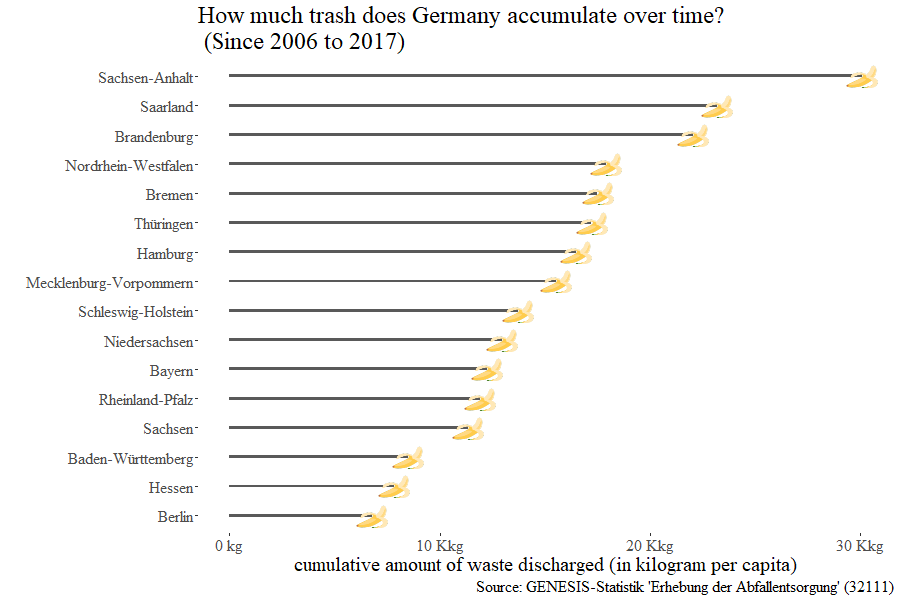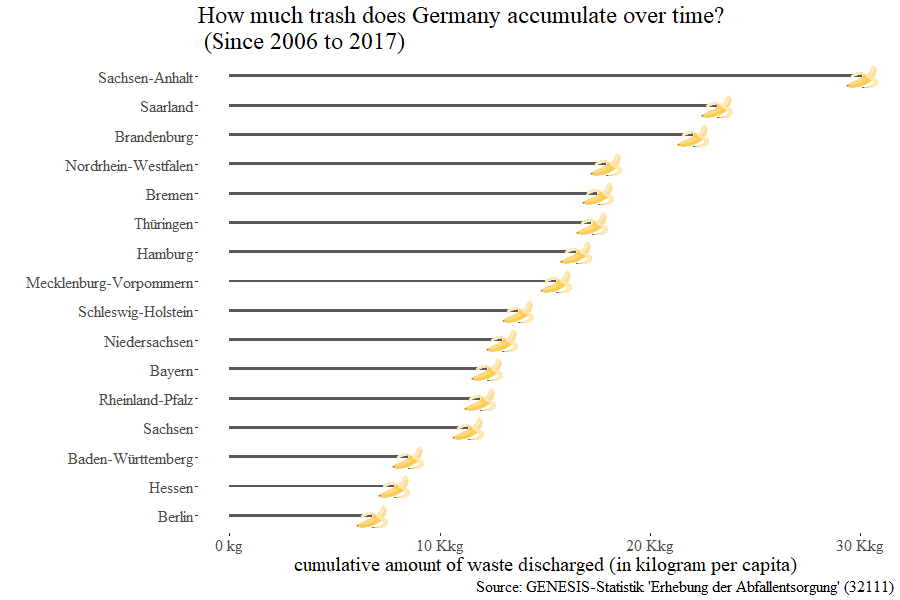
A major part of CorrelAid is the running of projects for NGO’s and the organization behind these projects. We spent our Sunday turning our gaze toward the inside, and figuring out how we can improve ourselves organizationally. Plans were announced for streamlining the way we tackle projects with CorrelAid Engage (coming Fall 2020), retrospecting on past projects with the lessons learned from these experiences, and taking a moment to examine the strategies of all our local chapters, including the international chapters of The Netherlands and Paris. We’re also proud to announce the start of CorrelAid X Berlin at the meetup.
It has been a whirlwind of a weekend filled with inspiration; a celebration of diversity in backgrounds, people, and skillsets; all with the shared goal to improve ourselves, and help society at the same time. If you’re interested in the workshops, presentations and codebases of this weekend, you can find them on our GitHub.
I’d like to thank all the organizers, speakers, and participants for making these 2,5 days an inspiring ball of chaos, fun and learning.

{kind=link}